- [OS/공룡책] Part 2. Process Management2024년 04월 23일 03시 20분 00초에 업로드 된 글입니다.작성자: @kimyu0218
One of the most important aspects of an operating system is how it schedules threads onto available processing cores.

프로세스A process is a program in execution.
프로세스는 실행 중인 프로그램을 의미한다. 프로세스의 활동 상태는 프로그램 카운터와 레지스터의 내용으로 알 수 있다.
프로그램은 실행 파일이 메모리에 로드되어야 프로세스가 될 수 있다. 프로세스의 메모리 레이아웃은 크게 네 가지로 나뉜다.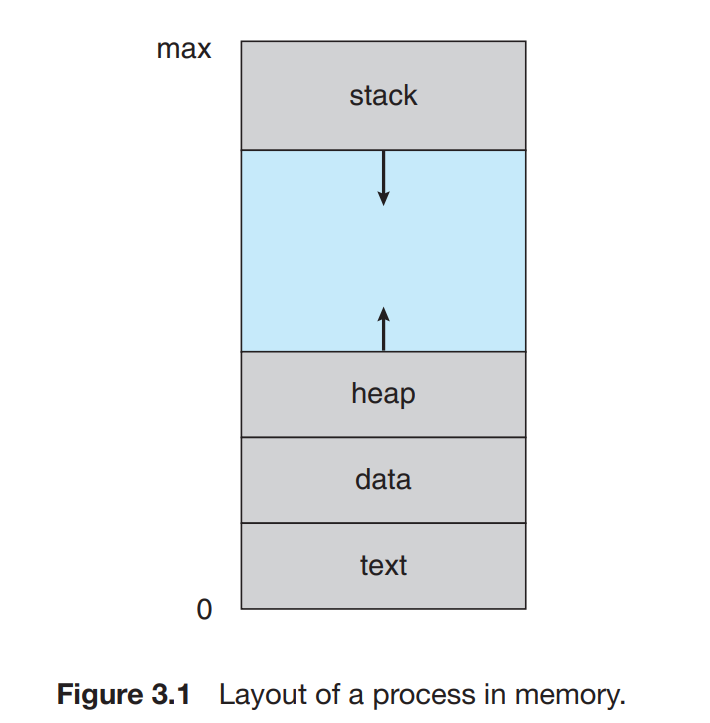
- 텍스트 영역 - 코드
- 데이터 영역 - 전역 변수
- 힙 영역 - 런타임동안 동적으로 할당된 메모리
- 스택 영역 - 함수 실행 시 함수 파라미터, 리턴주소, 지역 변수 같은 일시적인 데이터
텍스트와 데이터 영역은 런타임동안 그 크기가 변하지 않는다. 반면, 스택과 힙 영역은 프로그램 실행 중에 영역이 줄어들거나 증가할 수 있다. 이때, 운영체제는 스택과 힙이 서로의 영역을 덮어쓰지 않도록 관리해야 한다.
프로세스 상태
프로세스는 다음 상태 중 하나를 갖는다.
- new
- running
- waiting : 프로세스가 I/O 작업 완료 등 어떤 이벤트가 발생하기를 기다림
- ready : 프로세스가 프로세서를 할당받기를 기다림 (= 레디큐에서 CPU를 점유하기 위해 기다림)
- terminated

⭐ orphan 프로세스 vs. zombie 프로세스
- 프로세스는 마지막 문장의 실행을 끝내고 `exit()`을 통해 자신의 삭제를 요청한다.
- 자식 프로세스는 `fork()`에 의해 부모의 메모리 공간을 복사하여 생성된다.
- 부모 프로세스는 `wait()`을 이용하여 자식 프로세스가 종료되기를 기다릴 수 있다. `wait()`에 의해 프로세스의 자원이 운영체제에 반납된다.
- orphan 프로세스는 부모 프로세스가 먼저 종료되어 부모 프로세스를 잃은 자식 프로세스를 의미한다.
- zombie 프로세스는 자식 프로세스가 종료되었지만 부모가 아직 `wait()`을 호출하지 않아 메모리상에 정보가 남아있는 상태를 말한다.
PCB; Process Control Block
운영체제는 PCB를 기반으로 프로세스를 처리한다. PCB는 프로세스 상태, 프로그램 카운터 등 프로세스에 대한 정보를 담고 있다.
- 프로세스 상태
- 프로그램 카운터 (= PC) : 다음에 실행되어야 하는 명령어의 주소를 가리킴
- CPU 레지스터
- CPU 스케줄링 정보 (ex. 프로세스 우선순위, 스케줄링 큐 포인터 등)
- 메모리 관리 정보 (ex. base / limit 레지스터, 페이지 테이블, 세그먼트 테이블 등)
프로세스 스케줄링
멀티프로그래밍의 목표는 여러 개의 프로세스를 동시에 실행하여 CPU의 효율을 최대화하는것이다. CPU는 한 번에 하나의 프로세스만 실행할 수 있기 때문에 시분할을 통해 프로세스에게 번갈아 CPU를 할당함으로써 사용자가 프로그램과 상호작용하는 듯한 경험을 제공한다.
프로세스 종류
- I/O-bound 프로세스 : 계산보다 I/O 작업에 더 많은 시간 소요
- CPU-bound 프로세스 : I/O 작업보다 계산에 더 많은 시간 소요
프로세스가 처음 생성되면, CPU 코어를 점유하기 위해 기다리는 레디큐에 들어가게 된다. 프로세스가 특정 이벤트가 발생하기를 기다리고 있다면 대기 큐에 들어간다. CPU 스케줄러는 레디큐에 있는 프로세스중 하나를 선택하여 CPU를 할당한다.
Context Switch
앞서 말했듯이 CPU 코어는 한 번에 하나의 프로세스만 실행할 수 있다. 문맥은 PCB에 표현된 프로세스의 상태를 의미한다. CPU 코어를 다른 프로세스에 넘겨주려면 현재 프로세스의 상태를 저장하고 다음 프로세스의 상태를 복원하는 과정이 필요하다.
⭐ 문맥 교환 (개념 & 과정)
- 문맥 교환은 여러 프로세스를 처리해야 하는 상황에서 현재 진행중인 프로세스의 상태를 저장하고, 다음에 진행할 프로세스의 상태값을 읽어오는 과정이다.
- 현재 진행 중인 프로세스의 상태값을 PCB에 저장한다.
- 다음에 실행할 프로세스의 PCB 정보를 읽어 레지스터에 적재한다.
IPC; Interprocess Communication
프로세스 간 데이터를 교환하기 위해서는 IPC가 필요하다. IPC를 구현하는 방법은 크게 두 가지다.
- 공유 메모리
- 메시지 패싱

*생산자-소비자 문제 : 프로세스 간 상호작용을 위한 일반적인 패러다임이다. 생산자는 소비자가 사용하는 데이터를 생산한다.
공유 메모리
공유 메모리는 공유된 영역에 데이터를 읽고 쓰면서 데이터를 교환한다. 생산자와 소비자가 동시에 실행되기 위해서는 생산자가 버퍼를 채우고, 소비자가 버퍼를 비워야 한다.
#define BUF_SIZE 10 typedef struct { ... } item; item buf[BUF_SIZE]; int in = 0; // 생산자가 집어넣은 후 증가 int out = 0; // 소비자가 가져간 후 증가공유된 버퍼는 원형 배열로 구현한다. `in`은 다음에 집어넣을 위치를, `out`은 버퍼에서 처음으로 비워야 하는 위치를 가리킨다.
생산자, 소비자 코드는 다음과 같이 구현할 수 있다.// 생산자 ver. item next; while(true) { while((i + 1) % BUF_SIZE == out) {} // 포화 상태 buf[in] = next; in = (in + 1) % BUF_SIZE; }// 소비자 ver. item next; while(true) { while(in == out) {} // 공백 상태 next = buf[out]; out = (out + 1) % BUF_SIZE; }메시지 패싱
공유 메모리는 생산자와 소비자가 여러 명이 되면 로직이 복잡해진다. 메시지 패싱은 이를 커널에 위임한다. 메시지 패싱은 다양한 방법으로 구현될 수 있다.
- direct vs. indirect
- synchronous vs. asynchronous
- automatic vs. explicit
여기서는 직접적인 방법, 간접적인 방법에 대해서만 다룰 것이다. 직접적인 메시지 패싱은 송수신자를 명시하는 방식이다. 서로 다른 프로세스 간 하나의 링크만 존재할 수 있다.
P ↔ Q
반면, 간접적인 메시지 패싱은 포트를 통해 메시지를 주고 받는다. 서로 다른 프로세스 간에 여러 개의 링크가 존재할 수 있으며, 두 개 이상의 프로세스가 링크를 공유할 수 있다.# 서로 다른 프로세스 간 여러 개의 링크가 존재할 수 있다. P ↔ (A) ↔ Q P ↔ (B) ↔ Q # 두 개 이상의 프로세스가 링크를 공유할 수 있다. P ↔ (A) ↔ Q ↕ R
스레드
일종의 경량화된 프로세스
대부분의 현대 운영체제는 프로세스가 다수의 스레드를 갖도록 하여 한 번에 하나 이상의 작업을 처리할 수 있도록 지원한다. 멀티코어 시스템에서 스레드들은 병렬적으로 실행된다.
스레드는 스레드 ID, PC, 레지스터 집합, 스택으로 구성된다. 코드와 데이터 영역은 프로세스의 것을 공유하여 사용한다.⭐ 프로세스 vs. 스레드 (개념 & 메모리 공간)
- 프로세스는 컴퓨터에서 실행 중인 프로그램으로, 독립된 공간과 자원을 할당받는다.
- 스레드는 프로세스에서 실행되는 흐름의 단위로, 프로세스의 코드와 데이터 영역을 공유하고 각자 고유한 스택만을 할당받는다.
⭐ 스레드가 독립적인 스택을 가지는 이유
- 스택은 함수의 인자, 리턴 주소 등이 저장되는, 함수 호출에 사용되는 메모리 공간이다.
- 독자적인 스택은 독립적인 함수 호출이 가능하다는 것을 의미한다. 즉, 스레드는 고유한 스택을 할당받기 때문에 독립적으로 실행될 수 있다.
⭐ 스레드가 독립적인 PC를 가지는 이유
- PC는 다음에 실행되어야 하는 명령어의 주소를 가리킨다.
- 스레드는 CPU를 선점당할 수 있기 때문에 어디까지 진행했는지 즉, 다음 명령어의 주소를 저장할 필요가 있다.
멀티스레드
멀티스레드는 코어를 효과적으로 사용하여 향상된 동시성을 제공한다.
- responsiveness : 시간이 많이 소요되는 연산이 있어도 다른 스레드에서 사용자 요청을 처리할 수 있기 때문에 빠르게 응답할 수 있다.
- resource sharing : 프로세스의 경우, 자원을 공유하기 위해서는 공유 메모리나 메시지 패싱을 사용해야 하지만 스레드는 같은 코드, 데이터 영역을 갖기 때문에 자원 공유가 편리하다.
- economy : 프로세스에 비해 생성과 스위칭에 드는 비용이 적다.
- scalability : 각 스레드가 서로 다른 코어에서 병렬적으로 실행되므로 확장성도 뛰어나다.
💡 동시성 (concurrency) vs. 병렬성 (pararellism)
- 동시성 : 하나 이상의 프로세스를 실행할 수 있다.
- 병렬성 : 하나 이상의 프로세스를 동시에 실행할 수 있다.
🚨 프로그램들이 전부 병렬 처리되지 않는다면, 성능 향상에 한계가 있다. (암달의 법칙)
CPU 스케줄링
CPU scheduling deals with the problem of deciding which of the processes in the ready queue is to be allocated the CPU's core.
운영체제는 CPU 스케줄러를 통해 레디큐에 있는 프로세스 중 하나를 실행한다. 레디큐는 목적에 따라 FIFO 큐, 우선순위 큐, 트리, 연결 리스트 등 다양한 자료 구조로 구현될 수 있다.
💡 선점형 (preemptive) vs. 비선점형 (non-preemptive)
- 선점형 : 운영체제가 현재 실행 중인 프로세스를 중단시키고, 다른 프로세스에게 CPU를 할당한다. (= 강제적)
- 비선점형 : 한 번 CPU가 프로세스에 할당되면, 그 프로세스가 작업을 완료하거나 I/O 작업 등으로 대기 상태가 될 때까지 다른 프로세스가 CPU를 점유할 수 없다. (= 자발적)
💡 스케줄러 vs. 디스패처
- 스케줄러 : 어떤 프로세스에게 CPU를 할당할 지 결정한다.
- 디스패처 : 스케줄러가 선택한 프로세스에게 CPU 코어의 제어권을 넘겨준다. (= 문맥 교환의 주체)
스케줄링의 기준
- CPU utilization : CPU의 상태를 바쁘게 유지한다. 즉, CPU가 쉬지 않도록 한다.
- throughput : 단위 시간 내 완료된 프로세스의 수를 높인다.
- turnaround time : 프로세스가 완료되는 데까지 걸리는 시간을 최소화한다.
- waiting time : 프로세스가 레디큐에서 대기하는 시간을 최소화한다.
- response time : 프로세스가 처음으로 응답하기까지의 시간을 최소화한다.
⭐ CPU 성능 척도
- CPU utilization : CPU가 놀지 않고 일한 시간
- throughput : 단위 시간당 처리량 (= CPU가 얼마나 많은 일을 했는가)
- turnaround time : CPU를 사용한 시간 + 레디큐에서 기다린 시간
- waiting time : 레디큐에서 기다린 시간
- response time : 최초로 CPU를 얻기까지의 시간
스케줄링 알고리즘
가장 간단한 스케줄링 알고리즘은 FCFS (= First-Come, First-Served) 로, CPU를 가장 먼저 요청한 프로세스에게 CPU를 할당한다. FCFS는 FIFO 큐를 통해 쉽게 구현할 수 있다. FCFS는 convoy effect가 발생할 수 있는데, 이는 하나의 큰 프로세스가 작업을 완료할 때까지 다른 모든 프로세스가 대기하는 현상을 의미한다. FCFS는 CPU가 한 번 할당되면 이를 반환하기 전까지 강제로 중단할 수 없기 때문에 (non-preemptive) 평균 대기 시간이 길다.
SJF (= Shortest Job First) 는 여러 프로세스 중 CPU burst time이 가장 작은 프로세스에게 CPU를 할당하여 최소 평균 대기 시간을 보장한다. 가장 이상적인 알고리즘이지만 CPU burst time을 알 수 없기 때문에 예측하여 사용한다. SJF는 선점형, 비선점형 방식으로 구현할 수 있다. 선점형 SJF은 SRTF (= Shortest Remaining Time First) 라고도 부르는데, 남은 시간이 가장 짧은 프로세스를 선택한다.
RR (= Round Robin) 은 선점형 FCFS로, 프로세스를 time quantum이라는 작은 단위 시간동안 실행한다. 만약 CPU burst time이 time quantum보다 긴 경우, 인터럽트가 발생하여 문맥 교환이 이루어진다. RR 알고리즘의 성능은 time quantum의 크기와 연관이 깊다. time quantum이 너무 길면 FCFS와 동일하고 너무 작은 경우엔 문맥 교환이 빈번하게 발생하여 성능 저하로 이어진다.
우선순위 스케줄링은 우선순위가 높은 프로세스에 CPU를 할당한다. 앞서 등장한 SJF도 우선순위 스케줄링에 속한다. 우선순위 스케줄링에서는 starvation이 발생할 수 있는데, 이는 우선순위가 낮은 프로세스가 실행되지 못하고 레디큐에서 계속 기다리는 상태를 의미한다. SJF의 경우, CPU burst time이 긴 프로세스가 계속 대기하게 된다. 이는 에이징을 통해 무한정으로 대기하는 것을 방지할 수 있다.
FCFS SJF RR 우선순위 FIFO 큐 우선순위 큐 FIFO 큐 우선순위 큐 비선점형 선점형/비선점형 선점형 선점형/비선점형 convoy effect starvation - starvation 💡 멀티레벨 큐 vs. 멀티레벨 피드백 큐
- 멀티레벨 큐 : 각 큐는 자신만의 우선순위를 가질 수 있다.
- 멀티레벨 피드백 큐 : 멀티레벨 큐와 마찬가지로 큐별 우선순위를 가지고, 프로세스가 다른 큐로 이동할 수 있다.
'학습기록 > CS 공부' 카테고리의 다른 글
[OS/공룡책] Part 4. Memory Management (0) 2024.04.30 [OS/공룡책] Part 3. Process Synchronization (1) 2024.04.27 [OS/공룡책] Part 1. Overview (0) 2024.04.21 [OS] 커널 (모드 비트/시스템 콜/인터럽트) (2) 2024.02.12 [OS] 가상 메모리 (페이지 부재/페이지 교체/스레싱/워킹셋) (0) 2024.02.09 이전글이 없습니다.댓글