- [네트워크/KOCW] Chap3. Transport Layer2024년 06월 07일 15시 54분 08초에 업로드 된 글입니다.작성자: @kimyu0218
전송 계층은 end system에만 존재하는 계층으로, 라우터 같은 network core에는 없는 계층이다. 따라서 전송 계층은 네트워크 계층이 처리할 수 있는 데이터로 가공하여 전달해야 한다.
송신자 측의 전송 계층은 어플리케이션 계층으로부터 받은 메시지를 작은 단위 (segment) 로 쪼개고, 이를 네트워크 계층으로 전달한다. segment는 네트워크 계층에서 datagram으로 캡슐화되어 목적지까지 전송된다. 이때, 라우터는 segment의 내부 내용을 살펴보진 않는다.**네트워크 계층은 segment의 전송 여부, 순서, 무결성 등을 보장하지 않는다. (unreliable service)

전송 계층은 네트워크 계층의 바로 위에 존재한다. 네트워크 계층은 호스트 간의 논리적인 의사소통을 담당하는 반면, 전송 계층은 서로 다른 호스트에서 실행되는 프로세스 간의 논리적인 의사소통을 지원한다. 즉, 전송 계층은 네트워크 계층의 전송 서비스를 확장한다.
전송 계층에는 인터넷이 사용하는 두 가지 주요 프로토콜이 있다.UDP (user datagram protocol) TCP (transmission control protocol) reliability X O connection X O error-checking O O flow control X O congestion control X O multiplexing & demultiplexing
목적지의 전송 계층은 네트워크 계층으로부터 받은 segment를 적절한 프로세스로 전달해야 한다. 프로세스는 여러 개의 socket을 가질 수 있기 때문에, 각 socket을 구분할 수 있는 유일한 식별자가 필요하다.

송신측은 여러 socket으로부터 받은 데이터를 작게 쪼개고 캡슐화하여 네트워크 계층으로 segment를 전달한다. (multiplexing) 이때, socket을 구분하기 위해 소스 포트 번호와 목적지 포트 번호가 사용된다. 목적지의 전송 계층은 segment를 분석하여 (with 소스 포트 번호 & 목적지 포트 번호) 적절한 socket으로 전달한다. (demultiplexing)
UDP vs. TCP
TCP는 신뢰성 있는 데이터를 제공하기 위해 전송 전에 TCP 커넥션을 수립한다. 반면, UDP는 별도의 연결 없이 데이터를 전송한다. 이처럼 각기 다른 방식으로 동작하기 때문에 multiplexing과 demultiplexing에서도 차이가 있다.
UDP는 각 메시지가 독립적으로 처리되기 때문에 목적지 IP 주소와 목적지 포트 번호만으로도 충분히 소켓을 식별할 수 있다. 하지만 TCP는 각 커넥션을 유일하게 식별하기 위해 소스 IP 주소와 소스 포트 번호가 추가적으로 필요하다.
RDT; reliable data transfer
신뢰성 있는 채널에서는 데이터가 변경되지 않고, 손실되지 않으며 올바른 순서로 도착한다. TCP는 신뢰성 있는 데이터 전송을 보장하는 전송 프로토콜이다. 하지만 어떻게 신뢰할 수 없는 네트워크 계층 위에서 신뢰성 있는 서비스를 제공할 수 있을까?
rdt2.x (stop-and-wait, bit error)
수신자는 송신자 측에 bit error를 어떻게 알릴까? 컴퓨터 네트워크에서는 ARQ (automatic repeat request) 를 사용한다. ARQ 프로토콜이 bit error를 처리하기 위해서는 세 가지 기능이 필요하다.
- 에러 탐지 (ex. checksum)
- 수신자의 피드백 (ex. ACK & NAK)
- 재전송
수신자는 올바른 packet을 받으면 긍정적인 응답을 (ACK) , 에러나 손실이 발생하면 부정적인 응답을 (NAK) 보낸다. (`rdt2.0`) 송신자가 ACK이나 NAK을 기다리고 있다면, 수신자가 현재 packet을 잘 받았다는 확신을 얻기 전까지 새로운 데이터를 전송할 수 없다. (stop-and-wait)
해당 프로토콜은 RDT를 보장하는 것처럼 보이지만, 사실 치명적인 단점이 있다. 만약 ACK과 NAK에서 오류가 발생하면 어떻게 될까? checksum을 추가하면 수신자는 ACK/NAK이 손상되었는지 검사할 수 있지만, 송신자는 여전히 수신자가 마지막으로 전송된 데이터를 잘 받았는지 알 수 없다.
이 문제의 가장 간단한 해결 방법은 sequence number를 추가하는 것이다. (`rdt2.1`) stop-and-wait 프로토콜에서는 1 bit의 seq면 충분하다. 호스트는 0과 1을 번갈아가며 사용한다. 즉, 첫번째 packet에는 0을, 다음 packet에는 1을 할당한다.
만약 ACK/NAK에 오류가 있으면, 송신자는 가장 최근에 보낸 packet을 재전송한다. 수신자는 seq를 통해 전송된 packet이 새로운 것인지 재전송된 것인지 쉽게 구분할 수 있다.
그렇다면 NAK은 반드시 필요한 걸까? `rdt2.2`는 NAK 대신 가장 최근에 받은 packet의 ACK을 전송함으로써 이 문제를 해결한다. (= NAK-free)`rdt2.0` `rdt2.1` `rdt2.2` checksum O O O NAK O O X `rdt2.1` `rdt2.2` 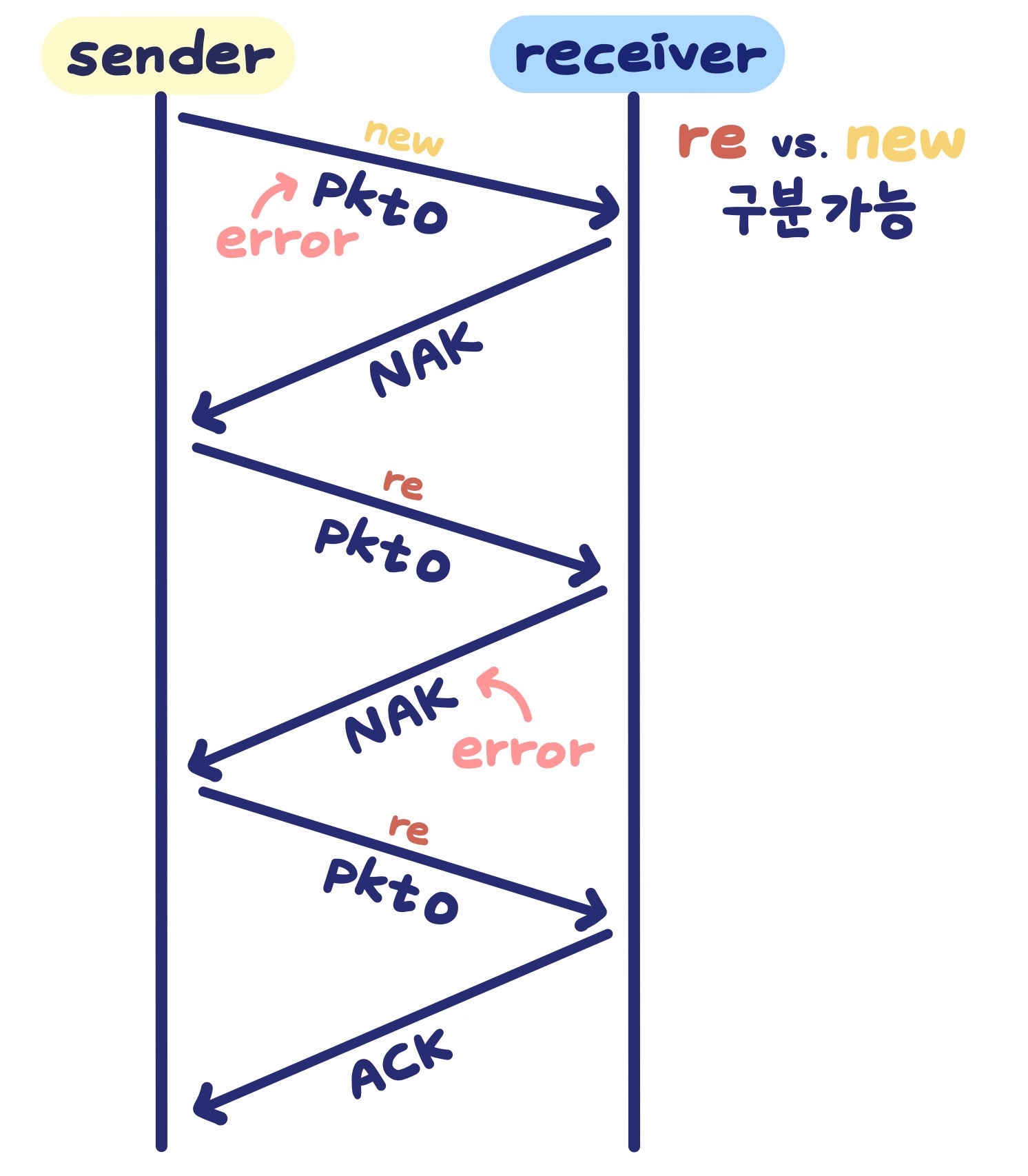

rdt3.x (packet loss)
신뢰적이지 않은 환경에서는 bit error 외에도 packet loss가 발생할 수 있다. 송신자는 타이머를 사용하여 일정 시간 기다림으로써 손실 여부를 확인할 수 있다. 만약 ACK이 일정 시간 내에 오지 않으면, 송신자는 packet을 재전송한다.
🚨 packet이 실제로 손실되지 않았음에도 불구하고, 타이머 설정 시간 동안 ACK이 도착하지 않을 경우, 송신자는 packet을 재전송하게 된다. 즉, packet이 중복으로 전송된다.
pipelined RDT
`rdt3.0`의 가장 심각한 성능 문제는 바로 stop-and-wait이라는 점이다. stop-and-wait은 수신자의 응답을 받기 전까지 다음 패킷을 보낼 수 없다. (하나씩 보내고 받기...!)
가장 간단한 해결책은 ACK을 기다리지 않고 여러 개의 packet을 연속적으로 전송하는 것이다. (pipelining) 대표적인 프로토콜로 GBN (Go-Back-N) 과 SR (Selective Repeat) 이 있다.- packet은 고유한 seq를 가져야 한다. (`rdt3.0`까지는 1-bit의 seq를, TCP는 32-bit의 seq를 갖는다.)
- 송수신자는 여러 개의 packet을 저장할 수 있는 버퍼가 필요하다.

GBN은 송신자가 N (= window size) 개의 packet을 ACK 없이 연속적으로 보낼 수 있도록 한다. (sliding-window) GBN에서는 cumulative ACK을 사용하는데, `ACK N`은 수신자가 N번까지의 모든 packet을 잘 받았음을 의미한다.

수신자는 out-of-order packet을 모두 버린다. 이는 수신자에게 잘 전달된 packet을 버리는 행위이기 때문에 비효율적으로 보인다. 하지만 TCP는 신뢰성 있는 데이터 전송을 보장하므로, 올바른 순서의 packet만 어플리케이션 계층으로 올려야 한다.
n번이 손실된 상태에서 n+1번을 버리지 않고 임시 저장한다고 가정하자. 추후에 n번이 도착하더라도 `ACK n`을 보내기 때문에 n+1번은 반드시 재전송된다. (중복 전송! 그냥 버리는 게 제일 간단하다) 따라서 GBN은 특정 packet이 손실되거나 오류가 발생하면, 해당 packet 이후로 전송된 모든 packet을 재전송한다.
window 크기가 큰 GBN에서 bit error나 packet loss가 발생하면 어떻게 될까? 하나의 packet에서 오류가 발생하더라도 많은 packet을 다시 전송해야 한다. SR은 오류가 발생한 packet만을 재전송하여 이러한 불필요한 재전송을 방지한다. 각 packet에 타이머가 존재하여 수신자로부터 해당 packet의 ACK을 받지 못하면 오류가 발생한 것으로 판단하고 재전송한다.
SR에서는 각각의 packet은 독립적으로 ACK을 받는다. out-of-order packet은 버려지지 않고, 손실된 packet이 전송되기 전까지 버퍼에 저장해 두었다가 어플리케이션 계층으로 전달된다.
UDP
UDP는 전송 프로토콜이 해야 하는 최소한의 일만 수행한다. demultiplexing을 위해 포트 번호를 붙이고, 이를 네트워크 계층으로 내려보낸다. 커넥션을 맺지 않기 때문에 handshake 작업도 하지 않는다.
DNS는 UDP를 사용하는 대표적인 어플리케이션 프로토콜이다. handshake를 하지 않기 때문에 (no connection establishment) 자원을 절약할 수 있으며 (no connection state) 빠른 응답을 받을 수 있다.
비디오 회의 같은 실시간 어플리케이션도 주로 UDP를 사용한다. 데이터 손실이 조금 발생하더라도 지연 시간을 최소화하는 것이 중요하기 때문이다. (소량의 데이터 손실이 발생하더라도 사람이 대체로 인지하지 못한다!)TCP
connection
TCP는 connection-oriented 프로토콜이므로 데이터를 주고 받기 전에 handshake 작업이 선행되어야 한다. handshake는 3단계 절차를 통해 이루어지며, 완료 후 커넥션이 수립된다.
- 클라이언트가 커넥션을 맺기 위해 서버에 SYN을 보낸다.
- 서버는 클라이언트에게 SYN-ACK을 보내 커넥션 요청을 수락한다.
- 클라이언트는 ACK을 전송하여 커넥션이 성공적으로 설정되었음을 알린다.
3-way handshake 4-way handshake 
TCP 커넥션은 full-duplex 통신을 지원한다. 이는 양쪽 호스트가 데이터를 동시에 송수신할 수 있음을 의미한다. (양방향+동시) 클라이언트 프로세스가 socket을 통해 데이터 스트림을 전달하면, TCP는 이 데이터를 커넥션의 송신 버퍼에 집어넣었다가 네트워크 계층으로 보낸다.

이때, segment에 포함될 수 있는 데이터의 최대 크기는 MSS* (maximum segment size) 에 의해 결정된다. TCP는 이미지 같은 크기가 큰 파일을 전송할 때, 일반적으로 파일을 MSS 크기의 덩어리로 나눈다.
*MSS : MTU (maximum transmission unit) 에 의해 결정된다. MTU는 네트워크 packet의 전체 크기를 의미하며, 기본적으로 1500B다.
segment
segment는 헤더와 데이터 필드로 구성된다. 데이터에는 어플리케이션 데이터가 들어있다. 지금부터 TCP 헤더에 대해 살펴보자.

- seq & ack : 신뢰성 있는 데이터 전송 보장
- receive window : 흐름 제어 보장 (수신자가 수용할 수 있는 정도)
- flag
- ACK = 유효한 ack 필드
- RST & SYN & FIN : 커넥션 수립/종료에 사용
segment에서 가장 중요한 부분은 seq와 ack으로, 이를 통해 신뢰성 있는 데이터 전송을 보장한다. 호스트 A가 호스트 B에게 파일을 전송한다고 가정하자. 파일의 크기가 500KB이고 MSS가 1KB라면, 호스트 A는 데이터 스트림을 500개의 segment로 나누고, 각 segment에 번호를 붙인다. (첫번째의 seq는 0, 두번째의 seq는 1000이다!) 호스트 B는 도착한 segment의 seq를 확인하고 ack에 다음 바이트의 seq를 넣어 보낸다.
💡 초기 seq (ISN) 는 랜덤하게 설정된다. 예측하기 어려운 숫자를 사용하여 보안을 높일 수 있으며, 이전 커넥션의 데이터와 섞이는 것을 방지한다.

RDT
TCP는 신뢰할 수 없는 네트워크 계층 위에서 신뢰성을 보장한다. 송신자는 3가지 이벤트를 통해 데이터를 전송하거나 재전송한다.
- 어플리케이션으로부터 데이터를 받고, segment로 캡슐화하여 네트워크 계층으로 전달
- 타임아웃이 발생한 segment 재전송
- ACK
하지만 타임아웃에 의한 재전송은 packet loss를 발견하고 대처하기까지 오랜 시간이 걸린다는 단점이 있다. fast retransmit은 이러한 지연을 줄이기 위한 방법으로, 동일한 번호의 ACK을 연속해서 여러 번 받을 경우, (duplicate ACK) packet loss로 해석하고 즉시 해당 packet을 재전송한다.
flow control
TCP 커넥션이 수립되면 커넥션을 위한 수신 버퍼가 설정된다. 수신 측 어플리케이션은 보통 다른 작업으로 바쁘기 때문에 데이터가 도착할 때마다 즉시 버퍼에서 읽어올 수 없다. 따라서 수신 버퍼에는 올바른 (correct & in-order) 데이터가 저장된다. 하지만 어플리케이션이 버퍼에서 데이터를 읽는 속도가 데이터 전송 속도보다 느리면, 너무 많은 데이터가 전송되어 수신 버퍼가 오버플로우될 수 있다.
이 문제를 방지하기 위해 TCP는 flow control 서비스를 제공한다. flow control은 송신자의 전송 속도와 수신 측 어플리케이션의 읽기 속도를 조절한다. flow control은 receive window라는 변수를 통해 이루어지는데, 이는 송신자에게 현재 수신할 수 있는 데이터의 양을 알려준다.
만약 수신 버퍼가 가득 차면 어떻게 될까? 더 이상 데이터를 전송하지 말라는 신호이기 때문에 송신자는 데이터를 보낼 수 없다. 하지만 포화 상태는 일시적이므로, 버퍼에 빈 공간이 생기면 송신 측이 다시 데이터를 전송할 수 있어야 한다. 이러한 문제를 해결하기 위해 receive window가 0인 경우, 송신자가 지속적으로 1B씩 보내 수신 버퍼의 상태를 확인한다.
congestion control

flow control을 하지 않아 수신 버퍼가 가득 차면 packet loss가 발생한다. 하지만 packet loss는 혼잡한 네트워크에서도 발생할 수 있다. (라우터의 버퍼가 가득 차서 packet loss 발생!)
congestion control에는 크게 두가지 방식이 있다.- end-to-end : 네트워크 계층의 지원을 받지 않기 때문에 간접적인 증거 (ex. packet loss, delay) 를 통해 혼잡 감지
- network-assisted : 네트워크 계층 장비들의 지원을 받아 혼잡 상태 정보 수집
하지만 network-assisted 방식은 네트워크 장비가 수행해야 하는 본연의 업무가 많기 때문에 end-to-end 방식을 더 선호한다.
end-to-end는 네트워크 장비의 도움 없이, 송수신자 간의 상호작용만으로 혼잡을 감지하고 제어하는 방식이다. 해당 알고리즘은 세 가지 주요 메커니즘을 갖는다.- slow start : 송신자는 혼잡 정도를 모르는 상태에서 네트워크 상태를 빠르게 파악하기 위해 window 크기를 2배씩 증가시킨다.
- congestion avoidance : window 크기가 임계값 (ssthresh = slow start threshold) 에 도달하면 window 크기를 점진적으로 증가시켜 혼잡을 피한다.
- fast recovery : 손실이 감지되면 window 크기를 줄이고 빠르게 혼잡 상태에서 벗어난다.

end-to-end에는 TCP Tahoe와 TCP Reno가 있다. 두 방식은 fast recovery에서 차이가 있다. Tahoe는 packet loss가 발생하면 window의 크기를 1로 설정한다. (back to slow start) 반면, Reno는 중복된 ACK이 세 번 연속으로 수신되면 손실로 판단하고, window 크기를 반으로 줄이고 선형적으로 증가시킨다. (back to congestion avoidance)
'학습기록 > CS 공부' 카테고리의 다른 글
[네트워크/KOCW] Chap4 & 5. Network Layer (0) 2024.06.10 [네트워크/KOCW] Chap2. Application Layer (0) 2024.05.31 [네트워크/KOCW] Chap1. Overview (0) 2024.05.28 [DB/쉬운코드] 파티셔닝과 샤딩 (0) 2024.05.18 [DB/쉬운코드] 인덱스 (EXPLAIN/B 트리) (0) 2024.05.16 이전글이 없습니다.댓글